
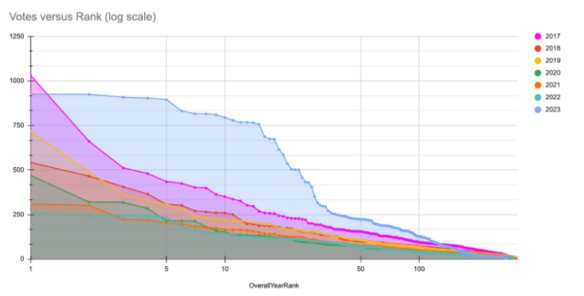
Introduction by Camestros Felapton: Since the release of the 2023 Hugo Award nomination statistics on January 20, there have been a plethora of questions about the awards and the process followed. One of the earliest insights into the data was made in a series of graphs drawn by Heather Rose Jones on her Alpennia (“A Comparison of Hugo Nomination Distribution Statistics”.) The graphs revealed several categories with highly unusual “cliffs” in the number of nominations.
This new report [available here] builds upon that initial analysis and delves further into the unusual features of the 2023 data. By collating data from all of the Hugo nominations from 2017 onward, the report looks at unusual features in the nomination statistics, compares 2023 with previous years in multiple dimensions and looks at additional data such as the recently leaked validation lists.
This report contends that the nomination statistics provided cannot be treated as a reliable presentation of the actual nomination votes by members. The report shows that there are known errors in the listed names of nominees, inconsistencies in the vote totals, inaccuracies in the manner points were calculated in elimination rounds and highly atypical patterns of voting. In particular, there is evidence in the categories of Best Novel and Best Series of a very large number of highly similar votes for the main finalists in these categories, that these votes advantaged English-language works over Chinese-language works and that these votes do not resemble organic voting by members.
The 51-page report can be downloaded from two locations:
File 770: “Charting the Cliff: An Investigation Into the 2023 Hugo Nomination Statistics”
Google Docs: ChartingTheCliff-Hugo2023
Discover more from File 770
Subscribe to get the latest posts to your email.
Clickity
[me emerging from my cave] you know…I think there might be something wrong with the 2023 Hugo Awards
Bat Mobile? Bat Bike? Bat Plane?
Remarkable work; thank you both!
(Though I hate the PDF format/ting, and there some annoying typos, most notably Cora “Bulhert”.)
The deeper we go, the worse this gets.
The word I am landing on to describe Dave McCarty and his Papal Bull is HUBRIS
Tremendous work!
We’ll never know what really happened unless the people involve start speaking a lot more honestly and informatively than they have in the past, but I have a pet theory (a cousin of the discredited Copy/Paste Names Theory) that I think is still alive and well after all this analysis:
Alleged slate votes for mostly Chinese-language works were removed, but their EPH points were not deleted from the system but rather distributed among small sets of mostly English-language works that were not treated as part of the alleged slates. (The total nomination counts, perhaps, were removed–maybe this is the “SQL error”?)
It explains the cliffs, the bizarre EPH-to-nomination ratios, and why the Chinese-language works generally have normal statistics and the English-language ones are all bizarre.
Of course, still purely speculative, but appealing on a number of axes.
At any rate, it’s discouraging to know that the released nomination statistics are meaningless for anything other than proving that something underhanded was going on. One of my favorite parts of participating in the Hugo Awards is scouring the longlist for obscure favorites who performed better than I expected. In an ordinary year, I’d have been thrilled to see The Mountain in the Sea as the top English-language work outside the finalist group. Unfortunately, I can’t trust that its votes were reportedly accurately, and the thrill has been taken away.
Off to read more about the 2023 nominations while I ignore the pile of things I should be looking at for 2024 nominations!
c4c
Excellent work by Camestros Felapton and Heather Rose Jones! Sadly, their investigation confirms the fears many of us had about these nomination stats not being trustworthy.
Well, that’s a nice chunk of data to poor through! Awesome work!
I really like the EPH-voting ratios – I think that’s the best quick synthesis of why we see the “cliff” from a data standpoint.
I know the stages of the proces are a conceptual one as described here.
but what strikes me from the validation sheet, is the question of how people worked with the validation sheet, and the invitation list. with people being copied into the validation sheet from the invitation list, and ( we suddenly have 2 ranked 7 candidates, nettle and bone, and Kaiju preservation society) and comments that state that names disappeared from the invitation list.
It feels to me, that there was an ongoing iterative process of data-tampering going on – at different stages of the finalist selection process.
Geez! This is worse than the Presidential election (almost)!
Hopefully, sanity will reign once again, and one vote will BE one vote.
This whole debacle only serves to diminish the Hugos in the eyes of outsiders/insiders/neutral observers.
Wow, that’s…actually a cliff. Thanks for the chart.
Wondering which analyses of the 2023 Hugos will get nominated for Best Related Work in 2025. The good stuff is coming out this year, so it’s too late for the 2024 Hugos.
It’s a cliff and just the tip of the iceberg!
Wondering which analyses of the 2023 Hugos will get “disqualified” for Best Related Work. (Yes, this is snark, but until we get a verifiable nomination process that all can trust … )
I’m kind of amazed at how comprehensively McCartney managed to f__k things up.
I mean, if you were placing bets beforehand, I have to think that someone trying to figure out the odds of “A Hugo admin arrogantly throws out 1000+ Chinese nominations because–as far as we can tell–he wanted to protect Westerners from being shut out” and “A Hugo admin cravenly eliminates nominated works that he’s worried could maybe possibly be problematic by Chinese norms” would have to admit that the chances of either were very small, but were at least non-zero.
The probability of the same Hugo admin doing both feels like something most people would assess as practically zero, because they reflect very different perspectives on what the goal here is.
But, here we are, with a process that, whether you’re pro-China, anti-China or just pro-Hugo, has something for everyone to hate.
Literally the only ones who might enjoy these results are the people who think the Hugos lost their way years ago, who will now point to McCartney’s claim that he was just doing what every Hugo admin does, as an admission that the results have been tainted for a while.
There’s something deeply ironic to me that a Hugo admin who just accepted that a Chinese Worldcon with Chinese voters would produce a practically-all-Chinese ballot would almost certainly have received next to zero personal criticism, because he’s just following the rules, and also wouldn’t have had to deal with any of the messy “How f__ked are we if another Hugo winner wants to use their speech to criticize the Chinese government?” questions, because the Chinese winners would be following Chinese norms and their works would have been pre-vetted by being publicly available in China.
Yes, I don’t think there is one neat process error but a series of changes some of which maybe genuine accidents.
What I would love would be if all of us working on documenting the 2023 Hugo mess combined our work, anthology-style, as a comprehensive reference work. Although, for that, we’d have to identify a point when we’re “done”.
Gary McGath: Is it hilarious or pathetic that anyone’s concern after reading these reports is about getting them nominated for the Hugo.
That is now fixed in the Google docs version https://docs.google.com/document/d/e/2PACX-1vSsNSBeLmp6MIuJX3ZEVTlw-Xj2AYygnz71j63aqnMFNvNSPxcFv-vSDgWFM17HFBN4r-Ap-nKGKaso/pub
I won’t generate a new PDF at this point as there surely must be more typos somewhere.
I can’t prove it but I think the cliff stats point to ballots being added thus boosting English-language works rather than ballots with Chinese works being removed but that is really just two different flavours of appalling with the same broad outcome.
Clicking
Based on the leaked list (and not accounting for how EPH might have shifted the 6th place etc or genuine eligibility issues), I think only Short Story would have been a clean sweep of Chinese-language works (many of which had translations in English). Novel would have had two strong English-language finalists (Babel and Daughter of Doctor Moreau). Novella would be mainly English language works. Series would be only one English (Scholomance). Other categories would have had fewer changes.
Dave McCarty has been working as a software developer for 32 years. One of the big mysteries of this scandal is why he would go to all the effort of writing new software to administer the Hugos and then spend so little effort covering his tracks.
Did anybody other than McCarty talk about the newly written software that was used, or have access to it during the administration of the 2023 Hugos? So far the only attempt to blame software error is coming from McCarty.
As some readers may vaguely recall, there were accusations of voting oddities in the nominations for the, e.g., 2015 awards, and many years ago accusations against Burroughs fandom of attempting to get I forget which for their hero. (this happened before many readers here were born). Someone with more graphical inclination and access to the needed data might or might not be able to see whether there are more low-count plateaus in those long-gone years.
@Cam
From what we’ve heard, Dave has been itching to be let off the leash to remove identical ballots since at least 2014. You cannot convince me that’s not at least part of the explanation here.
@George Phillies, N3F President
Heather Rose Jones’ comparisons do include 2015.
There was quietly organized slate voting in the Hugos for years before EPH, which was invented in reaction to a slate that occupied all or most slots on the final ballot.
EPH didn’t prohibit slate voting. It attempted to ensure that competing groups with different tastes or agendas would share the final ballot instead of any one dominating it.
It has failed. It is time to actually discourage slate voting. It could potentially be something as simple as awarding sets of multiple ballots with four or five identical works less than a full vote each.
But make it simple, transparent, easily auditable, and doable on paper with observers. Because otherwise, at this point, nobody’s ever going to believe anybody again.
I still say making the Hugos fully retro with paper-only ballots is the funnest solution.
What strikes me here is not so much the fuckery as the incompetence and haphazardness of the fuckery. It’s pretty clear we’re seeing a compromise of the Hugo vote on several different axes, with the vote being cooked in different ways at different times, with barely a token attempt at a fig leaf. That speaks to some combination of stupidity and sheer arrogance. Les Hugos, C’est Moi.
But what I don’t understand is given that there were 90 days to massage these numbers and make them look right, for a massively corrupt value of “right”, why didn’t DM do that? It was his software, he could have easily have numbers through it to achieve his desired results would have looked less obviously wrong.
Another thing that strikes me is that some people — not everyone, but some — are still trotting out the old chestnut about not ascribing to malice what could reasonably be explained by incompetence and attributing the bulk of the mistakes to software error or a ham-fingered copy and paste, except we know there was malice! We heard it from the leaky horse’s mouth! Given that, why anybody is continuing to give the benefit of the doubt and ascribing these results to innocent error is completely beyond me.
Laura: You’re right, though I suspect all George wanted was to throw shade on a couple more years.
@Brian Z
If this report doesn’t prove EPH’s worth to you, I really don’t know what to say. I liked it before, and now I am doubly pleased with it.
I can take just my own ballot and see in any category where I have something on the longlist and something else above if things are right or wrong.
After noticing so many things wrong on this year’s ballot, I realized that at least in Fan Artist my ballot was correctly counted and know that my votes weren’t completely tossed.
This also tells me that Dave’s software can work correctly. So there is no doubt that many of the problems were intentional, not accidental.
This may sound odd in the circumstances but I don’t think there was any slate voting in 2023.
Consider Best Novel. The evidence for slate voting is there:
1. High ballot numbers for a set of novels
2. High EPH ratios showing these novels tend to be on the same ballots as each other
OK, but there are SEVEN of these novels and people can only nominate FIVE. So this slate (of which nobody I know has heard a whisper of during the nomination process) has really good ballot discipline regardless (better than the Puppies in terms of sticking to the slate) AND is somehow coordinated well enough to have people following slightly different versions of the slate so as to cover seven nominees and yet still get relatively similar numbers of votes. And the people this slate manages to organise is SCIENCE FICTION fans. This is beyond herding cats, this is getting cats to march in formation and then perform a Busby Berkeley number.
But that’s not the end of it! Because not only do all these 700+ fans vote in strategic harmony BUT the votes of people who didn’t follow the slate that we never heard of somehow disappear (e.g everybody who voted for Mountain in the Sea and also voted for Babel). The marching synchronised swimming slate cats then perform a magic trick at the end of their show.
Yup.
Also, why did he release the stats in the end?
It all makes sense, if the Hugo committee was acting under the following assumptions:
– if there are too many Chinese entries on the ballot, Western fans will be upset.
– if the wrong kind of Western entries are on the ballot, the Party will be upset.
– what the Chinese fans think doesn’t matter, and no one that does matter can understand what they are saying or writing anyway.
The only thing that baffles me is what the role of the Chinese members of the Hugo committee actually was. Was it all McCarty and his English-speaking email correspondents?
All algorithmic approaches to nomination calculations (such as EPH) will reward and punish patterns in the nominations. For each work a system like EPH promotes to the final ballot, it removes a different one (absent when ties are created and the ballot is expanded.) As such it will be good for some, bad for others. EPH punishes works which share many ballots with other popular nominees which make the shortlist. It rewards candidates which don’t. The hope is that it punishes collusion, but it also punishes commonality of other types. It introduces “strategy” where you may decide to deliberately leave one candidate off your ballot if you suspect it will do fine without you, to aid a different choice. (In the old system you still might do that in the sense that you might leave off a popular choice to make room for a less popular one, now you might deliberately submit a smaller ballot or fill it without outliers.) Some hoped EPH might “discover” outliers, but it can only promote one candidate at the expense of others.
This is not to say that EPH’s effect has been giant. In the first year, other than puppies, it only eliminated one nominee who would have made it on the ballot under the old system. Ironically that was Patrick Nielsen-Hayden, partner of the host of the online forum where it was hatched.
It was a mistake then, and remain a mistake today. It’s the wrong approach to respond to active attack on the system. Yes, it provides an opportunity to uncover mistakes by inept hugo admins corrupting the process, but so would auditing of the ballot calculation, and more effectively.
Laura,
I was looking only at the graph in this article, which (print is small) seem to stop going back to 2017. I shall have to look more carefully at the other articles you kindly mentioned.
Thank you,
George
These are all good things. The net effect is sometimes the sixth finalist is something a somewhat different set of voters liked than the set of voters who picked the other five things. That’s just a plain good thing in a nomination process. You get a better ballot.
I think that’s quite subjective, and not just for the eliminated candidate and its fans. It’s not unknown for the last place nominee to be the winner, though it is more common for the winner to come from the top 3 (and it should be, or the system is clearly measuring the wrong thing.)
I don’t think you can make an objective determination, though, that one is better than the other. Though I will say that while EPH impedes a slate from taking over all slots on the final ballot, it perversely makes it much easier to get a single nominee on, and often two. For example in 2022, a group of 70 could place a work on all 4 fiction ballots, which would otherwise have needed 118. For Novellete and short story, a group of 30 could have done it, instead of 49. Though people sort of knew that. Flooding the ballot as the puppies did in a few categories needs large numbers. (You can’t assure a win because the fans will destroy the award to save it, and vote for No Award. Not a great outcome, of course.)
Of course, people differ on just what the nomination process is supposed to discover. It can be argued that it works as long as what would be the eventual winner in an omniscient contest makes the final ballot, as it will then defeat whatever else happens to make the ballot, though in reality humans can be found to prefer A>B, B>C but also C>A, known as a Condorcet failure, though that’s rare. The nomination process however, is also seen by some as a showcase, it exposes the winner but also some good work. For that EPH can elevate the more obscure at the expense of the mainstream, which some will see as a virtue, but not all.
It’s possible for the classic sum to miss that winner, but also possible for EPH to eliminate it.
My Hugo voting/nomination pattern hasn’t changed since EPH started (attn. Dave Quisling — THAT is the “rules we must all follow”). Nor has my like to dislike ratio of the finalists except in Pup years. I suspect this is the same with other Olde Pharts.
F’rex, I often left a sure thing off my ballot to mention a lower-chance work in hopes of boosting its visibility and getting it on the short list (or at least the long list) both before and after EPH. This goes back to my second vote in 1982. I nominate what I like.
Thanks to Heather and Cam for doing all the mathing for us.
@Heather: I agree that a grand unified math report would be a great thing. (And, yes, be eligible for BRW).
Also, I still have some of the orange peel you gave me a couple years ago — I had a nibble last week and it didn’t taste weird or kill me, so good job.
@Jon Meltzer: Welp, we know Dave and his North American buddies won’t be involved in the balloting this year, or any other, and the upcoming four scheduled Worldcons are in places that speak English (et Francais) and are in jurisdictions that broadly support freedom of speech, so we can hope there won’t be any need or perceived need to remove “problematic” works. Yes, there are still going to be things many of us will hate/find offensive, but they’ll get on the ballot nonetheless.
And yes, we’ve seen the Chinese fen on the Hugo committee apparently had little to no input on the decisions. That was all Pope Dave and his archbishops, as laid out in the leaked emails.
@Laura: Yes, Dave’s been keen to throw out things based on his personal preferences (except he didn’t toss any of the Puppy slates, which many people were hoping for) for at least a decade, if not more. And he really does think he’s always right, and he used his private proprietary software to count the Chengdu votes.
But then he couldn’t fudge the statistics well enough even on his very own software! He’d have been better off saying “the
dog ate my homeworknumbers are lost/corrupted, non-recoverable from big bad China, sorry” rather than waiting months to put out statistics that even the non-mathy thought looked weird. We’d have grumbled, but it would have died down.Kinda liking the idea of paper ballots again, although postage and mailing times from outside the host country is a bit of a barrier. Also, even as an Olde Phart whose voting goes back so far, I like the ability to change your rankings up to the last minute — which I have done, until 11:59:55 PM in the given time zone.
@Cam: I LOVED “Rabbit Test” and am thrilled it won, but it’s such a completely American story that the Chinese majority of voters wouldn’t have ranked it #1. If a Chinese story with an English translation won, we’d have all said, “Yup, makes sense, everyone thought that was good.”
Regardless of whether you do or don’t like the exchange, it allows for something that has strong but smaller overall support to make the ballot. I think that’s better even if it’s not something I would have chosen. The best “strategy” with EPH is to nominate as many of the things you think are worthy as you can.
Glad it was ratified. Glad it was re-ratified. And even more impressed now that I’ve seen how much else can be learned from it. This year unfortunately that’s mostly “ack! this is a mess!” But in years when it is done correctly it is much more interesting then just how many nominations each entry got. At least as interesting as how the final voting races play out if not more so.
That’s absurd. Why should a WSFS member have their nominations have less value than those of other nominators?
The four times that I’ve been a Hugo administrator (1998, 2002, 2006 and–yes–2015), I worked hard to make sure that every vote was counted and had the same value as every other other. To do otherwise is to violate the rules and spirit of the Hugos.
If a rules was passed such as that, that’s it for the Hugos for me. Forget being admin–I’d quit nominating and voting for a farce such as that, and would encourage everyone else to do the same. (On the other hand, Dave McCarty would be the perfect Hugo administrator for that rule.)
@Lurkertype
Because he was overruled. No one held him back this time. I don’t have a link handy, but someone on the 2016 team talked about it on bluesky.
@Lurkertype
It was a timely story for current US issues, but what made it so powerful was it showed the issue is actually timeless and universal.
I suppose the criteria I have for a better ballot are subjective:
1. it shouldn’t include things that definitely won’t win
2. it should help voters discover things that they might not know about but that they might like
3. it should be as varied as is feasible within those constraints
In most years and categories, finalists get a large minority of the votes i.e. less than 50% of the ballots cast in the category. On average the top nominee per category gets about 25% of the vote, i.e. it is endorsed by about a quarter of the people nominating. In the old system a rough grouping of about 26%ish of voters (who might not even think of themselves as a group, just people with similar tastes) could dominate a category. Getting some picks in from across the other 75% of people is, I think, a reasonably good idea that would fit most people’s sense of fairness when they think about it. he 5/6 rule helps here as well.
//it perversely makes it much easier to get a single nominee on, and often two//
Again, not perverse but how a system should work. Proportionality is generally a good thing in voting. More of the people who voted get something they liked on the ballot. The ballot ends up reflecting the likes and tastes of more of the members. These are all good things that we should want more of.
@Cam
These seem a little bit mutually exclusive to me. The last-place finalist that squeaks over the line might not have the same exposure as the first-place finalist. But it is only after the shortlist is announced that readers will get to experience that squeaker. Given the number of nominees is easily in the hundreds, there might be something in the 20th position on the long list that voters might prefer if they had a chance to read it.
The odds probably don’t run in that direction, but the possibility still exists. Particularly given the dearth of diversity in some categories.
Very nice job on the report, BTW and FWIW.
Regards,
Dann
War is an ugly thing, but not the ugliest of things. The decayed and degraded state of moral and patriotic feeling which thinks that nothing is worth war is much worse. John Stuart Mill
Brad Templeton: Though I will say that while EPH…
All the things you mention are all things that were heavily discussed in 2015 and 2016 by those who were working on a methodology to de-emphasize slate nominating.
And I know you were aware that those arguments were discussed at that time, because I’ve found a few similar comments made by you at that time.
I don’t why you think your opposition arguments to EPH then are going to carry any more weight with WSFS members now than they did then. (likewise, Brian Z.)
WSFS members haven’t gotten any stupider in the intervening 8 years. They’ve certainly gotten smarter about this subject.
I mean, you can keep beating this drum all you want — you’re not affecting anything, go right ahead — but don’t be surprised that you’re not having any effect.
Part of the argument for EPH is that it would produce a more varied ballot: if only a third of the people who are nominating like a subgenre (say, space opera), the ballot shouldn’t contain nothing but space opera. But it probably should contain some space opera. EPH tends to support both those goals.
If you’re sure that you and your buddies have better taste than everyone else, maybe you like the idea of an ballot with nothing but space opera. But all else being equal, a choice between the most popular novel in each of six different subgenres is more likely to give the Hugo to one of the best books of the year than a ballot limited to one subgenre.
Vicki Rosenzweig: a choice between the most popular novel in each of six different subgenres is more likely to give the Hugo to one of the best books of the year than a ballot limited to one subgenre.
A choice between the most popular novel in each of six different subgenres is also more likely to give Hugo voters a nudge toward fantastic works that they either haven’t heard of, or haven’t tried.
Camestros Felapton wrote: The marching synchronised swimming slate cats then perform a magic trick at the end of their show.
And somehow coordinate and execute the whole thing without a word getting out to anyone, unlike the Puppies who were only too happy to tell everyone what they were doing, every chance they got.
And as I understand it, the problem with the Puppy slates wasn’t that they nominated things they liked, but that they gamed the process in a way that excluded everything they didn’t like. Resulting in a ballot so massively unpopular that a majority found themselves preferring No Award. Nothing like that has happened since EPH, so I am skeptical of the claim that it has failed.