(1) SIGN FROM A FELINE. Mary Robinette Kowal’s “Rude Litterbox Space” is a free read at Sunday Morning Transport to encourage people to subscribe. Bonnie McDaniel says it is based on the author’s real-life communication-board-using cat.
… Language was hard. Bending space-time was not….
(2) A HITCH. P. Djèlí Clark’s blog post makes you want to read “The Dead Cat Tail Assassins”, then tells you why you’ll need to wait ’til summer’s end.
…Okay, now for the not so good news. The Dead Cat Tail Assassins was supposed to drop this month, March. But… yadda, yadda, yadda.. we got a new pub date: August, 6 2024.
What happened? Stuff. Stuff happened. Putting a book together requires lots of hands: me the author, editors, copyeditors, publicists, printers, centaurs, goblins, magical creatures from Fillory. And, for a myriad of reasons, sometimes things go pear shaped and stuff gets pushed back. You’re probably like, yeah but from March to August? That’s a big pushback! Hey, what can I tell you… lose your place in line, and you don’t just get a back-cut. There are other books by other authors waiting to be worked on, books coming out that can’t clash with your own, gotta find a new place in the queue at the printing warehouse, and all kinds of arcane alchemy I don’t pretend to understand…
(3) LIVESTOCK BY MAIL. I think the anecdote that starts Brian Keene’s “Letters From the Labyrinth 370” really happened, though I won’t be surprised if it finds its way into a book.
“I’m here about the dead chicks.”
That was what the woman butting in front of me and another customer at the post office said. I turned, intrigued. She was short, thin, blonde hair fading with age to the color of straw. I placed her at older than me — probably mid-sixties but then I remembered the day before when my postal carrier, whom I’d thought was in her seventies, told me she was the same age as me — 56. I can’t gauge age anymore. When I look in the mirror, I don’t see 56. But I’m also smart enough to know that how I see myself isn’t necessarily how others see me. In my mind, I’m still as suave and charming as Diamond David Lee Roth, but I suspect others look at me and think “Look at that silly old man. How sweet.”
But I digress….
Makes me remember when I was surprised to learn you could order live honeybees through the Sears catalog. (Which I wasn’t allowed to do. Just as well.)
(4) HUGO NEWS ROUNDUP AND MORE. Jason Sanford’s “Genre Grapevine for February 2024” on Patreon is free to the public.
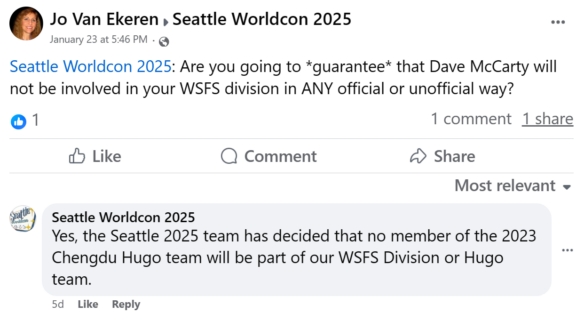
In early February, Chris Barkley contacted me and said he’d received emails and documents related to the 2023 Hugo Awards from Diane Lacey, one of the award administrators. I’d seen Chris only two weeks earlier at the ConFusion convention in Detroit, where we sat at the bar discussing that weekend’s release of the Hugo nomination and voting stats. We were both shocked by the works and authors deemed “not eligible” and kept off the final ballot for no stated reason. We also were surprised so few Chinese authors and works made the Hugo longlist.
While talking in Detroit, Chris and I felt shenanigans had likely happened during last year’s Hugos. However, we also feared the truth of what happened might never come out.
Two weeks later, Chris shared the leaked emails and documents and I realized we’d been wrong. The truth would indeed come out….
(5) FAITH. Abigail Nussbaum walks readers through “The 2024 Hugo Awards: My Hugo Ballot” at Asking the Wrong Questions. She says in a preamble to the nominations:
We’ve spent so much of the last six weeks talking about the debacle that was last year’s Hugo awards, that it was easy to forget that another awards season was gearing up at the same time. So here we are, with less than a week left to nominate for this year’s Hugos, and to be honest it feels a bit strange to make this post. I always love to talk about the things I enjoyed in the fantastic genres over the last year, and to encourage my readers to consider them for a Hugo nomination. But doing it this year, with the shadow of an award whose nominations and results we can have no faith in, can feel a bit pointless.
Another way of putting it is that this is an act of faith–in the administrators of this year’s award, who have been doing their utmost to project reliability and distance themselves from last year’s inexcusable actions; in the fandom, which continues to care about this award and try to make it the best it can be; and in the award itself, and the idea that it can overcome this blow to its reputation and start moving back to what it was….
(6) KGB. Fantastic Fiction at KGB reading series hosts Ellen Datlow and Matthew Kressel present Christopher Rowe and Moses Ose Utomi on Wednesday, March 13 starting at 7:00 p.m. Eastern. Location: KGB Bar, 85 East 4th Street, New York, NY 10003. (Just off 2nd Ave, upstairs)

Christopher Rowe

Christopher Rowe’s most recent novella, The Navigating Fox, published by Tordotcom was described by The Wall Street Journal as a “modern Aesop’s fable.” His other books include the novella These Prisoning Hills and a collection, Telling the Map. Over the last 25 years, his stories have been published, anthologized, and translated around the world and he has been a finalist for the Hugo, Nebula, World Fantasy, Theodore Sturgeon, Neukom, Seiun, and other awards. He lives in Kentucky.
Moses Ose Utomi

Moses Ose Utomi is a Nigerian-American fantasy writer and nomad currently based out of San Diego, California. He has an MFA in fiction from Sarah Lawrence College and short fiction publications in Fantasy Magazine, Sunday Morning Transport, and other venues. He is the author of the young adult fantasy novel Daughters of Oduma and The Forever Desert, the fantasy novella series that includes the acclaimed The Lies of the Ajungo. When he’s not writing, he’s traveling, training martial arts, or doing karaoke—with or without a backing track.
(7) FILM EDITING AWARDS. Deadline has the “ACE Eddie Awards Winners List”.
Oppenheimer took the marquee Best Edited Feature Film (Dramatic) honor and The Holdovers landed the top Best Edited Feature Film (Comedy) award at the 74th ACE Eddie Awards Sunday….
Here are all the winners of genre interest:
BEST EDITED FEATURE FILM (Drama, Theatrical)
- Oppenheimer — Jennifer Lame
BEST EDITED ANIMATED FEATURE FILM
- Spider-Man: Across the Spider-Verse — Michael Andrews, ACE
BEST EDITED DRAMA SERIES
- The Last of Us: “Long, Long Time” — Timothy A. Good, ACE
(8) HERE WE GO AGAIN. “Hollywood Teamsters, IATSE Hold Solidarity Rally Ahead of AMPTP Negotiations” – The Hollywood Reporter was there.
A coalition of Hollywood’s below-the-line unions rallied Sunday on the eve of their latest contract negotiations. They threatened a historic strike against the Alliance of Motion Picture and Television Producers if their demands weren’t met. Such a work stoppage would follow a pair of strikes in 2023 by industry writers and actors which crippled the entertainment industry and have left it limping into the new year.
“I hope they’re paying attention right down the road at the AMPTP,” IATSE vice president Michael Miller announced from the stage to the crowd of around a thousand people at Woodley Park in Encino. (Nearly a thousand more watched a live-stream online.) He then invoked a slogan repeated throughout the event: “Nothing moves without the crew.”
For the first time since 1988, the Hollywood Basic Crafts group — which includes Teamsters Local 399, IBEW Local 40, LiUNA! Local 724, OPCMIA Local 755 and UA Local 78 — and the crew union IATSE are joining this year to negotiate their health and pension benefits with the Hollywood trade group the AMPTP, which represents studios and streamers. Those talks begin Monday.
The “Many Crafts, One Fight” rally served mainly as an opportunity for members to express solidarity and hype each other up. So-called “above-the-line” unions SAG-AFTRA and the WGA made strong shows of force with their sign-wielding members and leaders expressing gratitude. (Teamster cooperation was key in the WGA’s production shutdown strategy early in its stoppage.) WGA West vice president Michele Mulroney drew applause when she acknowledged crew support which “sustained us through our own long and arduous fight,” and noted that “without all of you our words would just languish on the page.”…
(9) ARRAKIS DELIVERS BIG B.O. “’Dune 2′ Nears $100 Million Overseas, Surpasses $150 Million Globally” according to Variety.
“Dune: Part Two” is turbocharging the international box office.
Director Denis Villeneuve’s otherworldly sequel has generated $97 million from 71 overseas markets, bringing its global tally to a promising $178.5 million. Those worldwide revenues include $81.5 million from North American theaters, where it landed the biggest domestic opening weekend of the year.
The movie, starring Timothée Chalamet and Zendaya, has been embraced in the U.S. and Canada. But the backers of “Dune 2” need overseas audiences to keep the ticket sales flowing as freely as spice on the desert planet of Arrakis. That’s because Warner Bros. and Legendary Entertainment spent $190 million to produce and roughly $100 million more to promote the film to global audiences. Those hefty fees mean the tentpole will require outsized admissions to turn a profit.
(10) MARK DODSON (1960-2024). The voice actor Mark Dodson died of a heart attack while staying in Evansville, IN to appear at Horror Con. Deadline pays tribute: “Mark Dodson Dies: ‘Star Wars’ And ‘Gremlins’ Voiceover Artist Was 64”.
Mark Dodson, whose unique voice characterizations propelled creatures in the films Star Wars: Return of the Jediand Gremlins, has died at 64.
His daughter told TMZ that he died while in Evansville, Indiana, to attend Horror Con. He checked into a hotel and suffered a “massive heart attack” while sleeping, she said.
Dodson was the voice of Salacious Crumb, the scruffy little creature who was a cackling crony of Jabba the Hut in Star Wars: Return of the Jedi.That memorable voice led to a gig in Gremlins, where he became the voice Mogwai, much-imitated in school yards.
He worked continuously for several decades in film, video games, radio and commercials as a voice artist. .
His daughter, Ciara, told TMZ that her father “never ceased making me proud.” a
The Evansville Horror Con, where Dodson was scheduled to appear, posted a tribute to Facebook.
“We are heartbroken to announce the sudden passing of Mark Dodson last night. Mark was not only a talented voice actor but also a cherished member of the horror community. Our thoughts and prayers are with his family, friends, and fans during this incredibly difficult time. We hope that you can take a moment out of your day to reflect on the joy and laughter that Mark brought into the world. His legacy will live on through his work.”
Survivors include his daughter and several grandchildren.
(11) TODAY’S BIRTHDAY.
[Written by Cat Eldridge.]
Born March 3, 1920 — James Doohan. (Died 2005.) James Doohan, a Canadian, is of course remembered best for being the original Montgomery “Scotty” Scott on the first version of the Enterprise. And doesn’t it say something about the franchise that I had to write the sentence that way?

He played, definitely way too much in my opinion, the archetypal Scotsman. He even had a Dress Uniform Kilt, something I’m dead certain doesn’t exist in the modern Navy, as on display in “Is There in Truth No Beauty?” and “The Savage Curtain”. And I forget how many characters he drank literally to the floor. No don’t get me wrong, I loved the character, but the depiction was seriously over the top.
So my favorite episode involving him? That had to be when he defended the honor of the Enterprise in a bar brawl with a Klingon in “The Trouble with Tribbles” after that Klingon called his beloved ship a garbage scow. Perfect, just perfect.
So what else has he done? His first major genre role (he had previously appeared in one episode of Tales of Tomorrow) was as Paul Mitchell on Space Command, an early Fifties Canadian children’s sf series. It only lasted two years but they did one hundred and fifty episodes! Shatner would appear there.
A decade later, he entered the Twilight Zone playing Johnson, by no means a major role, in the “Valley of the Shadow”. Around the same time, on Outer Limits he played Police Lt. Branch in “Expanding Human”, this time a lead role.
He showed up twice in The Man from U.N.C.L.E (in different roles), Bewitched, Fantasy Island, MacGyver and Knight Rider 2000.
Need I say Next Generation’s “Relics” was wonderful? And I’m not talking about Trials and Tribble-ations even though it’s a stellar story as he’s only there in existing footage of him.

Filmwise, Trek was his major gig as I see very little genre undertakings at all. He had an uncredited role in The Satan Bug, an sf thriller. It’s so short that IMDB gives the time that he’s in the film.
His only other genre role that I can see in a film outside of Trek was as Judge Peterson in Skinwalker: Curse of the Shaman. If you’ve not seen it don’t feel bad. It’s obscure enough that no one on Rotten Tomatoes has either.
I think that covers it for him. Now keep in mind that I did love him, despite my criticism of his portrayal of a Scottish character, on Trek as he’s really likeable. He and Nichelle Nichol’s always seems to be the two most, well, truly warm, likeable individuals there.
I think I’ll go watch both of the Tribbles episodes on Paramount + now. Yes, I know there’s the animated episode as well, “More Tribbles, More Trouble”, but it just doesn’t have the charm the actual ones with live actors do.
(12) COMICS SECTION.
- Wallace the Brave is being hopeful.
(13) CACHING IN. [Item by SF Concatenation’s Jonathan Cowie.] If my memory serves (and it is not that reliable though I constantly amaze myself in recalling a science paper from years ago out of the recesses of my mind) I have a feeling that File770 covered the demise of Google’s readily available Cache. Then this piece might interest you — “Why Is Google Hiding Its Cached Search Results?” at Tedium.
I have to imagine that Google did not make a lot of money from people pinging its search engine for cached website results, but making it convenient to access was a service to searchers.
It was also somewhat of a service to society. Often, when information-related scandals broke—such as content with egregious errors, evidence of deleted social media statements, or information at risk of appearing offline in short order—it was a great backstop that worked more effectively than the Internet Archive for capturing fresh information.
And yet, for some reason, Google has treated this feature like it was embarrassed of it. Over the years, it has increasingly come to bury the feature in its search interface, making it harder and harder to find, despite me finding it just as useful as it was the day it launched.
Recently, the company started removing it entirely…
… To be clear, the cache is not gone—it is simply hidden from public view. (I don’t see it on my end, either.) You can access it manually by typing in a specialized URL…
For example, here’s the URL to access the cache for File 770: https://webcache.googleusercontent.com/search?q=cache:file770.com
(13) A TRUTH NOT YET UNIVERSALLY ACKNOWLEDGED. Would Jane herself have turned thumbs down on this idea? “Winchester plan for £100,000 Jane Austen statue triggers ‘Disneyfication’ fears” reports the Guardian.
The idea was to celebrate one of the greatest British authors with a beautiful statue set up in a cathedral for the 250th anniversary of their birth.
But at a public meeting to discuss the erection of a Jane Austen sculpture close to her final resting place at Winchester Cathedral, concerns were raised that it would lead to the “Disneyfication” of the place of worship and become a magnet for tourists keen to get a selfie.
Elizabeth Proudman, an Austen expert and leading light in the Jane Austen Society, also suggested the author herself would not have approved of the statue and the fuss surrounding it.
She said: “We don’t know what she looked like, but we do know that she was a very private person. She despised publicity.”
Austen is buried in the north nave aisle of Winchester Cathedral under a memorial stone, which mentions “the extraordinary endowments of her mind” but does not provide any more detail about her career.
(15) IN CASE YOU WONDERED. Everyone who’s read the history of the first atomic bomb saw this was missing from the movie. SYFY Wire’s James Grebey gives his opinion “Why Oppenheimer Doesn’t Include the Deadly “Demon Core” Accidents”.
… The ominously named demon core, a sphere of plutonium used in the development of atomic bombs after the success of the Trinity Test, was responsible for the deaths of two scientists who worked on the Manhattan Project. The core, which weighed 14 pounds and measured just 3.5 inches in diameter, was all set to be turned into a third bomb that could have been used against Japan had they not surrendered following the bombings of Hiroshima and Nagasaki in August 1945….
(16) THE HILLS ARE UNDEAD WITH THE SOUND OF MUSIC. Mitch Benn mashes up “Gilbert & Sullivan’s Francis Ford Coppola’s Bram Stoker’s Dracula” for YouTube viewers.
Now with on-screen libretto, my “restoration” of Gilbert & Sullivan’s operetta version of Dracula married to the sumptuous visuals of Coppola’s masterful 1992 film adaptation… Have fun with it before someone has it taken down
(17) VIDEO OF THE DAY. In a 2018 video Mr. Sci-Fi, Marc Scott Zicree, explains “WHY DIDN”T WE GET THIS?! Unreleased Sulu Star Trek Series!”
Star Trek and Deep Space Nine writer Marc Scott Zicree shares the entire Captain Sulu Star Trek pilot he and Emmy winner Michael Reaves wrote, and shares the untold story of why you never got to see that series — despite its Hugo and Nebula Award nominations!
[Thanks to SF Concatenation’s Jonathan Cowie, Steven French, Mike Kennedy, Kathy Sullivan, Bill, Andrew Porter, John King Tarpinian, Chris Barkley, and Cat Eldridge for some of these stories. Title credit belongs to File 770 contributing editor of the day Bill.]